
1.创建抽象和执行抽象
在并行开发或并发开发过程中,免不了要创建线程,然后执行线程。如果每一个线程都要一一手工创建和执行,会带来两个问题:
- 太繁琐。创建线程和执行线程的代码会把真正的业务代码淹没,代码可读性变差;
- 容易创建过多线程,造成资源浪费。每个线程都会占用内存,创建线程也需要占用CPU时间。
对于创建线程,Java并发包采用的是工厂模式。对于执行线程,Java并发包采用的是把任务交给线程池。下图是创建抽象和执行抽象的关系图:
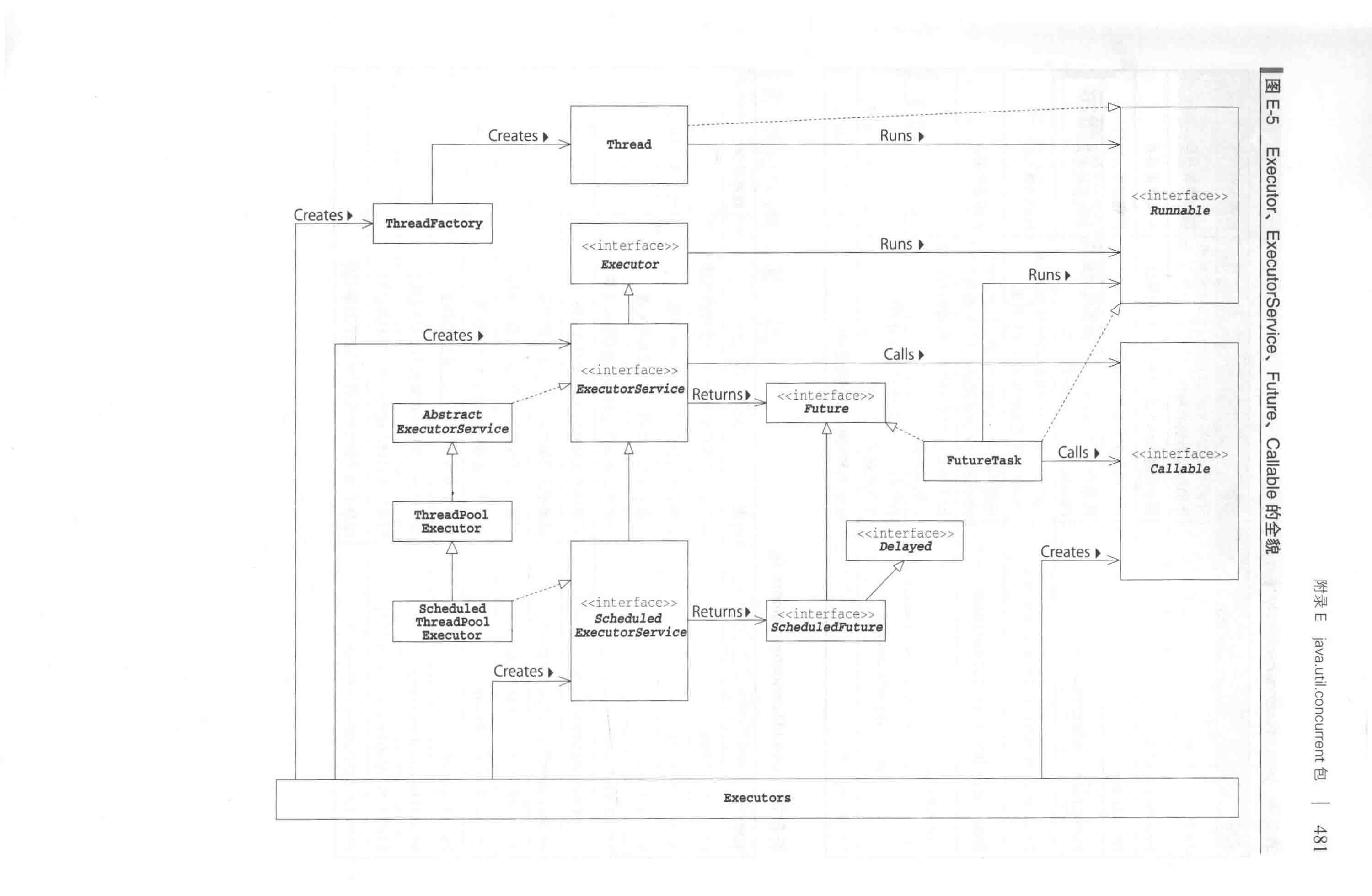
一切都可以从Executors工具类开始,Executors可以创建线程工厂ThreadFactory,线程工厂决定创建线程的细节。Executors还可以创建线程池,线程池控制着线程数量和线程的生命周期。最后由线程池调度线程工厂创建好的线程去执行任务。
最后代码就变成只要把任务对象扔进线程池,任务就会被自动执行。不用再一个个创建和执行。代码变得简洁的同时,线程占用的资源也得到了自动控制。
2.线程池介绍
线程池大概可以分为三类:
- ThreadPoolExecutor 普通线程池,下面介绍创建ThreadPoolExecutor的所有参数:
- corePoolSize 线程池可以一直持有的线程数量(不会一开始就创建这么多线程,懒创建),这些线程不会过期;
- maximumPoolSize 最多可以有多少线程,当需要的线程大于corePoolSize,就会临时创建线程,但是不能超过maximumPoolSize;
- keepAliveTime 临时线程空闲存活时间;
- unit 时间单位;
- workQueue 工作队列。当任务在被执行之前会放在工作队列里面。工作队列里面只能存Runnable对象。Callable会先转化成对应的Runnable然后进入工作队列;
- threadFactory 线程工厂
- handler 当线程数量达到maximumPoolSize之后,而且工作队列满了,就会拒绝处理。这个handler就是确定拒绝策略的处理器。
- ScheduledThreadPoolExecutor 定时线程池,可以替代java.util.Timer。
- corePoolSize 线程池一直持有的线程数量,这些线程不会过期;
- threadFactory 线程工厂
- handler 当线程数量达到maximumPoolSize之后,而且工作队列满了,就会拒绝处理。这个handler就是确定拒绝策略的处理器。
- ForkJoinPool 分支/合并线程池
- parallelism 线程数量,默认是CPU个数;
- factory 线程工厂;
- handler 执行异常处理器;
- asyncMode 异步模式,如果为true就是异步模式,默认false。
这三种具体的线程池实现,分别用于不同的场景,ThreadPoolExecutor用于通用任务,ScheduledThreadPoolExecutor用于定时任务,ForkJoinPool用于符合分支/合并模型的计算密集型任务。Excutors工具类可以抽象地创建这三类线程池:
- newFixedThreadPool(int nThreads):ExecutorService。固定线程数量的线程池。corePoolSize=nThreads,maximumPoolSize=nThreads,临时线程执行完任务马上过期(事实上没有临时线程),工作队列是一个LinkedBlockingQueue容器,所以工作队列长度没有边界;
- newFixedThreadPool(int nThreads, ThreadFactory threadFactory):ExecutorService。同上,不过指定线程工厂;
- newSingleThreadExecutor():ExecutorService。只有一个线程的线程池。临时线程执行完任务马上过期(事实上没有临时线程),工作队列是一个LinkedBlockingQueue容器,所以工作队列长度没有边界;
- newSingleThreadExecutor(ThreadFactory threadFactory):ExecutorService。同上,不过指定线程工厂;
- newCachedThreadPool():按需创建线程池。corePoolSize=0,maximumPoolSize=2147483648,临时线程执行完任务1分钟后过期(全是临时线程),工作队列是一个SynchronousQueue,这种队列生产者和消费者总是同步执行,size永远是0;
- newCachedThreadPool(ThreadFactory threadFactory):ExecutorService。同上,不过指定线程工厂;
- newSingleThreadScheduledExecutor():ScheduledExecutorService。单个线程的定时线程池。
- newSingleThreadScheduledExecutor(ThreadFactory threadFactory):ScheduledExecutorService。单个线程的定时线程池。指定工厂方法;
- newScheduledThreadPool(int corePoolSize):ScheduledExecutorService。指定核心线程个数的定时线程池;
- ScheduledExecutorService newScheduledThreadPool(int corePoolSize, ThreadFactory threadFactory):ScheduledExecutorService。指定核心线程个数的定时线程池。指定线程工厂;
- newWorkStealingPool():ExecutorService。Fork/Join线程池,线程数量为CPU数量;
- newWorkStealingPool(int parallelism):ExecutorService。Fork/Join线程池,线程数量为指定数量。
总结:
- 具体的线程池实现有三类,Executors工具类提供了12种抽象创建线程池对象的方法,用于分别创建这三类线程池对象。返回的线程池对象都抽象成了ExecutorService或ScheduledExecutorService,这是两个抽象类。
- ExecutorService提供用于执行任务的方法是submit方法。submit方法最终都会调用execute方法,如果submit方法接收的是Callable,就会先转化成Runnable,然后传给execute方法。对于固定数量的线程池和单个线程的线程池,工作队列长度没有限制。对于按需创建线程池,工作队列长度为0。
- ScheduledExecutorService提供用于执行任务的方法是schedule*方法,schedule方法会先把任务放进工作队列,等待调度执行。在执行的时候可以指定延迟时间delay和执行周期period。
- 对于Fork/Join线程池,只适合执行符合Fork/Join模型的计算密集型任务,线程数量默认为CPU个数就行。
- 线程、工作队列和任务的关系:从execute方法开始,当发现线程池里面的线程数小于corePoolSize(也就是说不会一开始就创建corePoolSize个线程),就会创建线程并直接执行,当发现线程数等于corePoolSize,就会把任务先放进工作队列等待,当工作队列满了,就会创建临时线程,当线程数量达到maximumPoolSize,并且工作队列满了,就会拒绝服务。当临时线程空闲下来,就会在指定时间后销毁。
3.线程工厂
ThreadFactory,顾名思义,就是创建线程的工厂。一般来说,每种线程池都有默认的线程工厂,使用默认的就行了。如果自己自定义线程工厂,可以保留一些线程的元信息和统计信息,方便定位和监控。比如记录创建了哪些线程,创建时间是什么,总共创建了多少个线程……
ThreadFactory只有一个方法,就是通过任务创建线程:
public interface ThreadFactory { Thread newThread(Runnable r);} 4.Future模式
当我们把一个任务交给一个线程进行执行后,往往希望得到执行结果。这时可以利用Future模式获取。关键接口和类的关系图如下:
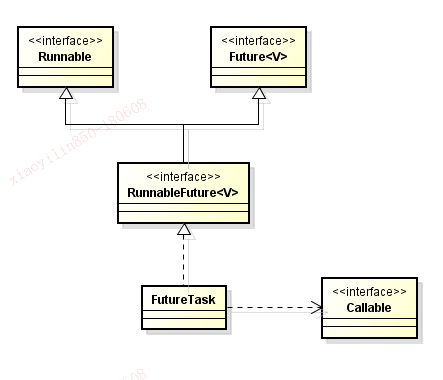
FutureTask是一个Runnable,所以可以当做一个线程任务。在构建FutureTask的时候,需要注入一个Callable对象,当执行FutureTask的run方法的时候,就会执行Callable对象的call方法,call方法返回的结果就会当做FutureTask对象的一个成员变量。调FutureTask的get方法的时候,就返回这个成员变量的值。
其实,Runnable和Callable根本不是一个概念的东西,Callable不是线程任务,Callable最终都要转化为Runnable,才能被线程执行。下面是一段伪代码,简单展示一下Future模式的实现原理:
public class FutureTask implements Runnable,Future{ private Callable callable; private String result; @Override public void run() { try { result = callable.call(); } catch (Exception e) { } } @Override public String get() throws InterruptedException, ExecutionException { //等待逻辑 ... return result; } ...}
5.总结
本文阐述了线程的创建、执行以及结果获取,Java并发包通过巧妙的抽象,让这些操作变得简单易于管理。所以,我们写生产代码的时候,一般不需要自己手工一一地创建线程、执行线程、获取线程的结果……用这些抽象工具就行。